Und wieder ein Eintrag, bei dem „unterschätztes Tool“ nicht den Kern der Sache trifft: InfluxDB begegnet ein im Moment so oft, dass man es kaum unterschätzen kann. Trotzdem bin ich erst jetzt dazu gekommen, mich intensiver damit zu befassen und war recht erfreut.
In der guten alten Zeit™ war rrdtool das Mittel der Wahl: Es ist (relativ) einfach zu benutzen, die Daten benötigen konstanten Platz und durch das automatische Zusammenfassen der Werte behält man die Daten über eine längere Zeit, dann aber mit reduzierter Genauigkeit. Das Erzeugen von statischen Grafiken ist einfach; man kann für die Darstellung im Browser sowohl Bitmapgrafik (PNG) als auch Vektorgrafik (SVG) auswählen. Alles in allem ein extrem praktisches Tool, das zu recht weit verbreitet ist.
Andererseits hat rrdtool doch einige Nachteile: Die Daten werden pro Messpunkt in einer Datei gehalten, die beim Aufruf der Kommandos neu eingelesen wird. Es gibt keine Serverkomponente, die auch remote Zugriff auf die Daten regelt. Programme, die mit den Daten arbeiten wollen, benutzen direkt die Datei. Falls man in einer Datei die Messwerte und die Zeiten festgelegt hat, kann man diese Einstellungen nur noch schwer ändern. Außerdem sind die erzeugten Graphen zwar sehr informativ (falls die Werte es sind), aber statisch.
Mit dem Duo InfluxDB und Grafana kann man einen zeitgemäßen rrdtool-Ersatz bauen. InfluxDB ist dabei die Datenhaltungskomponente, Grafana ist die Visualisierungskomponente.
InfluxDB
InfluxDB ist eine in modischem Go geschriebene Serveranwendung, die auf Zeitserien spezialisiert ist. Eine moderne/modische Fähigkeit, um die ich mich im Folgenden nicht kümmern werde, weil ich sie mangels Zeit und Bedarf nicht getestet habe, ist die Clusterfähigkeit. Wie jede modernere NoSQL-Datenbanksoftware verspricht InfluxDB Clusterfähigkeiten mit Replikation und Ausfallsicherheit.
Als Datenbanksystem kann es – wie bei gewöhnlichen SQL-Datenbanken – mehrere verschiedene Datenbanken verwalten. Der Aufbau einer einzelnen Datenbank unterscheidet sich aber deutlich von einer SQL Datenbank. Statt Tabellen gibt es Messungen (»measurements«). Ein einzelner Messpunkt besteht aus Tags (über die man suchen kann) und Werten mit dem Zeitpunkt als zentraler Information. Innerhalb einer Messung gibt es Serien (»series«), das sind Datensätze mit den gleichen Tags:
> SHOW SERIES […] name: load_shortterm -------------------- _key host type load_shortterm load_shortterm,host=localhost,type=load localhost load load_shortterm,host=squeeze32.local.konfusator.de,type=load squeeze32.local.konfusator.de load […]
was dann in der Messung so aussieht:
> select * from load_shortterm order by time desc limit 4 name: load_shortterm -------------------- time host type value 1456001944328022000 localhost load 0.26 1456001941673827000 squeeze32.local.konfusator.de load 0 1456001934328659000 localhost load 0.31 1456001931670654000 squeeze32.local.konfusator.de load 0
Man erkennt, dass man im CLI-Client an SQL angelehnte Abfragen machen kann.
Bisher ist es – bis auf eigene Nomenklatur – noch nicht sehr ungewöhnlich gewesen. Interessant wird das ganze mit zwei Konzepten: Den Retention Policies und den Continuous Queries.
Zu jeder Datenbank gehören eine oder mehrere Retention Policies, die tatsächlich das sind, was der Name verspricht: Speicherregeln. Das betrifft zum einen die Anzahl der Replicas, aber viel entscheidender die Haltedauer. Jede Datenbank hat eine Default Retention Policy. Falls dort eine Haltezeit festgesetzt ist, werden die Messpunkte nach erreichen der Haltezeit gelöscht. Das ist etwas, was man vom rrdtool kennt. Mit Retention Policies kann man schon mal das unbegrenzte Wachstum von Daten verhindern.
Will man aber Daten über einen längeren Zeitpunkt mit möglicherweise geringerer Auflösung aufheben, kommen die Continuous Queries ins Spiel. Ein Continuous Query ist eine durchgehend laufende Anfrage, die Daten zusammenfassen und in eine andere Retention Policy kopieren kann.
Das ganze sieht man am Besten an einem Beispiel:
> show retention policies on collectd; name duration replicaN default zwei_wochen 336h0m0s 1 true ein_jahr 8760h0m0s 1 false zehn_jahre 87600h0m0s 1 false
Die Anzahl der Replicas ist hier mangels Cluster immer eins. Ansonsten entsprechen die Namen der Haltezeit. Die mit der zweiwöchigen Haltezeit ist als default gesetzt. Dazu kommen dann die folgenden Continuous Queries (die ich zur besseren Übersicht umgebrochen habe):
name: collectd
--------------
name query
collectd_downsample_15m CREATE CONTINUOUS QUERY collectd_downsample_15m ON collectd
BEGIN SELECT mean(value) AS value INTO collectd.ein_jahr.:MEASUREMENT
FROM collectd.zwei_wochen./.*/ GROUP BY time(15m), * END
collectd_downsample_12h CREATE CONTINUOUS QUERY collectd_downsample_12h ON collectd
BEGIN SELECT mean(value) AS value, max(value), min(value)
INTO collectd.zehn_jahre.:MEASUREMENT
FROM collectd.zwei_wochen./.*/ GROUP BY time(12h), * END
Zwei Sachen an diesen Queries sind wichtig. Zum Einen ist da die Kombination aus dem regulärem Ausdruck FROM collectd.zwei_wochen./.*/ für die Quelle und collectd.ein_jahr.:MEASUREMENT als Ziel, was dafür sorgt, das jedes Measurement bearbeitet wird. Der zweite wichtige Punkt ist das », *« im GROUP BY – ohne das würden die Tags verschwinden, was bei vielen Eingabedaten völlig sinnlos wäre (weil in einem Measurement mehrere Series stecken können, die sich nur nach den Tags unterscheiden). Schließlich sieht man auch, dass man im Query auch neue Werte erzeugen kann – in collectd_downsample_12h merke ich mir zusätzlich den maximalen und den minimalen Wert im entsprechenden Intervall.
Grafana
Grafana ist eine Visualisierungslösung, die sich nicht auf InfluxDB beschränkt – sie kann auch Graphite und OpenTSDB als Quelle benutzen. Wer aus dem ELK-Stack Kibana kennt, kann sich vorstellen, was Grafana machen kann.
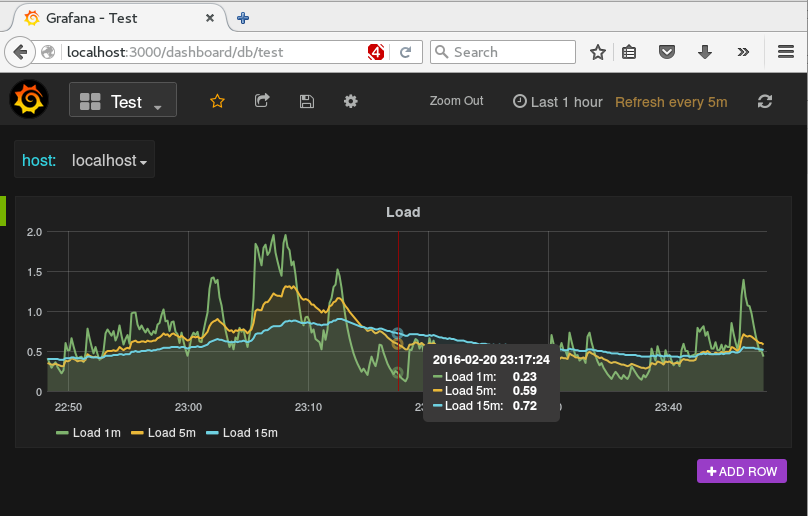
An diesem Beispiel sieht man einige der Möglichkeiten: Verschiedene Hosts (die als Tags in den Measurements stehen) können über ein Pulldown-Menü ausgeählt werden. Details zu einzelnen Punkten gibt es onmouseover. Nicht zu sehen aber trotzdem nützlich ist Möglichkeit, einzelne Grafen per Mausklick abzustellen.
Allerdings muss man sich auch in Grafana einarbeiten und es gibt auch einiges, was man per Hand erledigen muss. Die Retention Policy beispielsweise muss man explizit angeben; bei 2.6 kann man sie auch (noch) nicht grafisch auswählen.
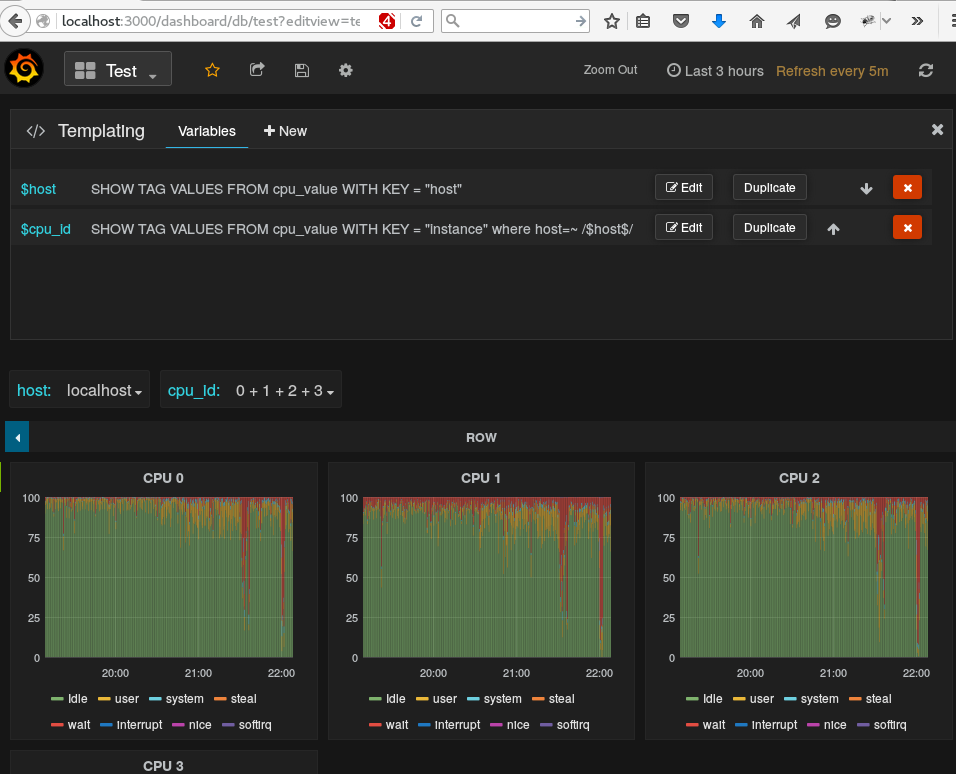
Das Pulldown Menü erhält man über Dashboard Templating – man muss da eine Variable definieren und zum Füllen einen Query wie
SHOW TAG VALUES WITH KEY = "host"
hinterlegen. Man kann es sogar noch weiter treiben und – wie unten im Screenshot gezeigt – Templates mit abhängigen Variablen erzuegen. In diesem Screenshot wird pro Host die Zahl der CPUs ermitelt. Das Auswahlmenü zur cpu_id ändert sich dann in Abhängigkeit von der ausgewählten Maschine. Auch die Graphen pro Core sind nicht mehrfach erzeugt, sondern mittels „Repeat Panel“ von Grafana erzeugt.
Schließlich sei noch erwähnt, dass man die JSON-Definitionen der Grafana-Dashboards exportieren und auf anderen Maschinen wiederverwerten kann.
Das soll zunächst reichen – ich bin sicher, dass ich über diese Werkzeuge später noch mehr schreiben kann.